Discover how Job-ID-based segmentation secures and optimizes backend AI fabrics, ensuring high-performance connectivity for demanding AI and machine learning workloads at scale. Discover how Job-ID-based segmentation secures and optimizes backend AI fabrics, ensuring high-performance connectivity for demanding AI and machine learning workloads at scale. Read More Data Center - Cisco Blogs
AI clusters are becoming a shared infrastructure. Neoclouds, enterprise AI platform teams, financial services organizations, life sciences teams, and research groups need to share GPU capacity. This shared infrastructure can suffer from lower monetization, increased operational complexity, and limited control and visibility across tenants, workloads, hosts, and the network fabric.
EVPN/VXLAN is the practical network foundation. It provides tenant-scoped overlay segmentation using VRFs, VNIs, route distinguishers, and route targets. However, tenant-aware segmentation is not job-aware segmentation. The scheduler understands jobs; the network typically understands routes, interfaces, queues, drops, and flows.
Dedicated GPU clusters are simple to isolate, but they are inefficient to operate at scale. As GPU estates grow, organizations want a shared resource pool that can serve multiple teams, customers, and workload classes without forcing every group into its own physical cluster. Otherwise, one group can have stranded GPUs in a dedicated island while another waits in queue.
The requirement appears in several patterns:
This is why multitenancy cannot stop at compute allocation. Distributed training depends on east-west GPU communication, typically over Ethernet fabrics, so the network becomes an integral part of the isolation and performance boundary.
Current AI multitenancy is usually implemented across three layers:
ACLs or security group ACLs can add source and destination policy, especially in brownfield L3 designs or where the fabric cannot yet consume richer workload identity. Their limitation is operational scale: static or manually updated ACL and VRF policies do not naturally follow fast-changing AI job placement.
Together, these layers provide a workable tenant-level model. The remaining gap is job context: the network can usually see tenant context, interfaces, routes, queues, and counters, but not the specific scheduler job running inside a tenant. Tenant segmentation itself does not automatically isolate Job 100 from Job 101 inside the same tenant unless job identity is also carried, derived, or programmed into network policy.
Cisco Nexus One is well positioned as the broader foundation for making tenant-aware AI fabrics more deterministic. In this architecture, Nexus One is the complete fabric automation, integration, and visibility surface for the entire fabric.
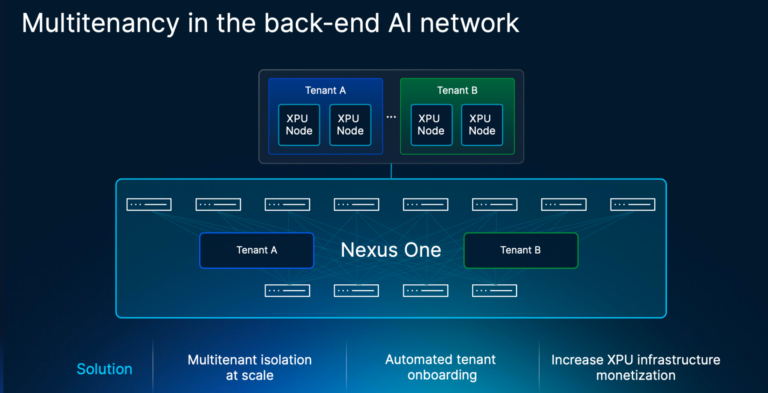
Nexus One can provide fabric topology context to an AI infrastructure orchestration platform such as Rafay through integration workflows or APIs. That lets teams map tenant VRFs, VLANs, and port assignments directly to a tenant, rather than managing them only as an abstract tenant label.
In addition, Nexus One extends the model beyond provisioning. Tenant-level visibility can show the tenant’s fabric path and relevant health signals such as congestion, drops, and so on. This complements AI job observability: job-aware views can correlate scheduler, topology, optics, GPU telemetry, analytics, and anomalies, while tenant-specific Job-ID enforcement remains a separate future-facing policy capability.
Tenant segmentation answers the question, “Which customer or organization owns this traffic?” AI operations often need, “Which training job is creating or experiencing this traffic within a tenant?”
This distinction matters for segmentation as well as during troubleshooting. A scheduler can identify the job, allocated nodes, GPUs, and runtime state. The network can identify interfaces, routes, queues, drops, ECN marks, PFC events, optics health, and paths. Without correlation, operators must manually connect these two views.
The result is a common operational problem: the fabric shows a hot uplink or lossy interface, while the platform team sees a slow training job. The missing link is the workload identity in the network operating model.
Job-ID-aware segmentation direction—patent-pending technology from Cisco—is the logical next step. (Note that this describes our architectural direction, not a shipping feature.) The goal is for infrastructure orchestrator (such as Rafay) and scheduler (such as Slurm) intent to carry both tenant identity and job identity into the fabric control and data-plane model.
In that model, the fabric controller translates job intent into policy. The switch data plane carries or derives a job ID, for example through VXLAN GPO bits, and enforces that only endpoints in the same authorized tenant and job can exchange RoCEv2 traffic.
The expected benefits are operationally important:
This approach is built on open standards—not a proprietary overlay. EVPN/VXLAN is IETF-defined, and the Group Policy Option (GPO) follows the same path: an IETF-defined mechanism that encodes a group/policy identifier in the VXLAN header alongside the VNI, which Cisco NX-OS implements in alignment with the open specification. Tenant scope (VNI) and workload/job scope (GPO) are therefore expressed in constructs a standards-compliant fabric can interpret—letting operators evolve from tenant-aware to job-aware enforcement without a fabric forklift.
Consider a GPU-as-a-Service environment with two customers, Tenant A and Tenant B. Each tenant is mapped to its own VRF/VNI in the EVPN/VXLAN fabric. Tenant-level segmentation prevents Tenant B from reaching Tenant A.
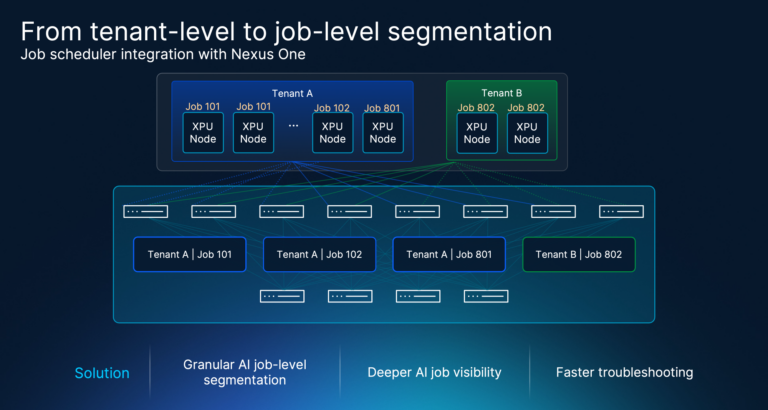
Now assume Tenant A runs two concurrent training jobs. Job 100 uses GPUs on servers 1 and 2. Job 101 uses different GPUs on the same shared fabric. Tenant-level EVPN/VXLAN still treats both jobs as Tenant A traffic. Job-ID-aware segmentation would add another enforcement dimension: Job 100 endpoints could exchange RoCEv2 traffic with other Job 100 endpoints, but not with Job 101 endpoints, even inside the same tenant.
That is the architectural shift: EVPN/VXLAN remains the tenant foundation, while Job ID becomes the future workload-level policy and observability attribute.
AI data center multitenancy starts with EVPN/VXLAN tenant segmentation, but it does not end there. The stronger operating model combines topology-aware provisioning, tenant-level enforcement, and end-to-end visibility today, then evolves toward Job-ID-aware segmentation as scheduler and orchestrator integration matures.
If you are designing a shared AI cluster today, tenant-aware EVPN/VXLAN is the foundation. Job-aware enforcement and observability are the next frontier.
*Special thanks to Ramesh Ponnapalli and his team, whose engineering leadership has been instrumental in bringing this technology to life.
Read more about this innovation
Additional resources: